In my day job at Red Hat I work on the os-migrate project which allows users to migrate their workloads from one Openstack deployment to another.
The project uses ansible to achieve this.
My colleague has a nice write up on os-migrate @ https://www.jistr.com/blog/2021-07-12-introduction-to-os-migrate/ and you can see the official docs @ https://os-migrate.github.io/os-migrate/.
I am working on a new feature and I need to be able to debug my code changes in a nice debugger where I can step through and inspect code.
With ansible collections this isn’t as easy as regular python script or web projects as the ansible playbooks are by default run from the `~/.ansible` directory after installation using ansible-galaxy.
I use Pycharm primarily and with the help of Deepak Kothandan’s excellent Debugging Custom Ansible Modules with PyCharm post I have found a very neat way to debug the os-migrate ansible collection using the Python Debug Server built in to Pycharm and a local python virtual environment.
These are the steps I followed:
- Install the pydevd-pycharm module in your python virtual environment
pip install pydevd-pycharm~=212.5284.44 # this will differ for your installed Pycharm version- Create a “Python Debug Server” Run/Debug configuration to start the debug server
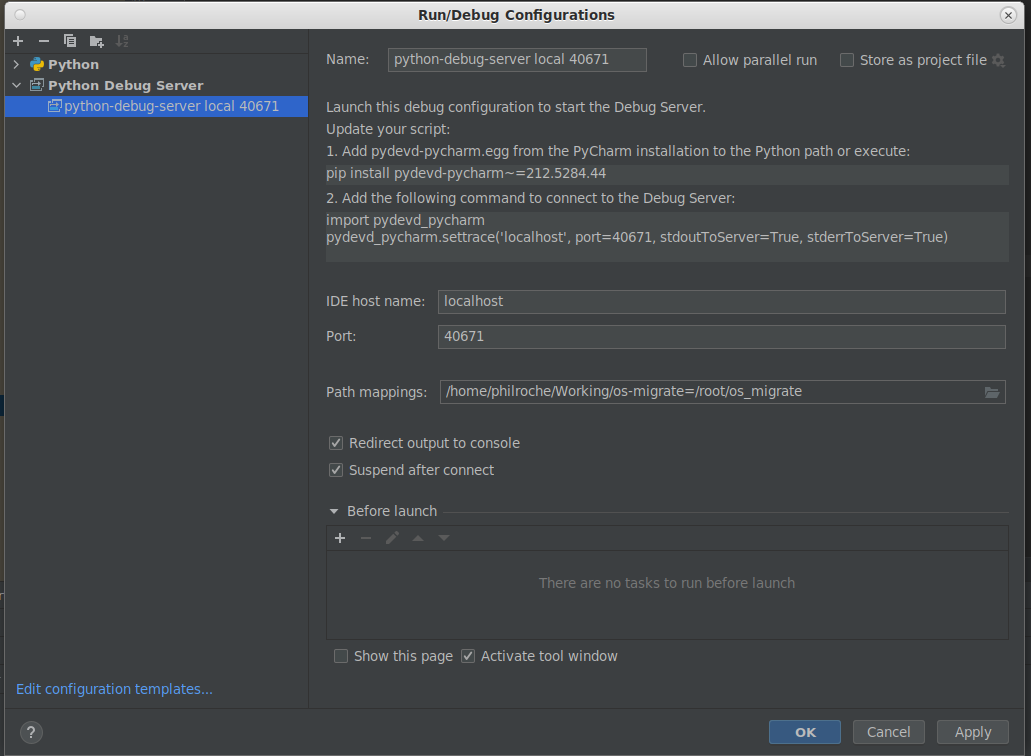
- Start the Debug server
- Add
settracecode to the code you wish to debug
import pydevd_pycharm
pydevd_pycharm.settrace('localhost', port=40671, stdoutToServer=True, stderrToServer=True) # The port number here might differ depending on your debug configuration above- Build and install your ansible collection so your up to date code is used
For os-migrate I can use our Makefile to do this
make reinstall- Run the code you wish to test either manually or using a different Run/Debug configuration in Pycharm. In the snippet below I am running the export networks playbook using my custom auth creds.
export OSM_DIR=/home/philroche/.ansible/collections/ansible_collections/os_migrate/os_migrate
export CUSTOM_VARIABLES="/home/philroche/Working/os-migrate/local/proche-variables.yaml"
export CUSTOM_VARIABLES_OVERRIDE="/home/philroche/Working/os-migrate/local/proche-variables-local.yaml"
export OSM_CMD="ansible-playbook -vvv -i ${OSM_DIR}/localhost_inventory.yml -e @${CUSTOM_VARIABLES} -e @${CUSTOM_VARIABLES_OVERRIDE}"
$OSM_CMD $OSM_DIR/playbooks/export_networks.yml- When the
settracecode is reached then a debug session is started in Pycharm allowing you to step through and into your code in the Pycharm debugger interface.
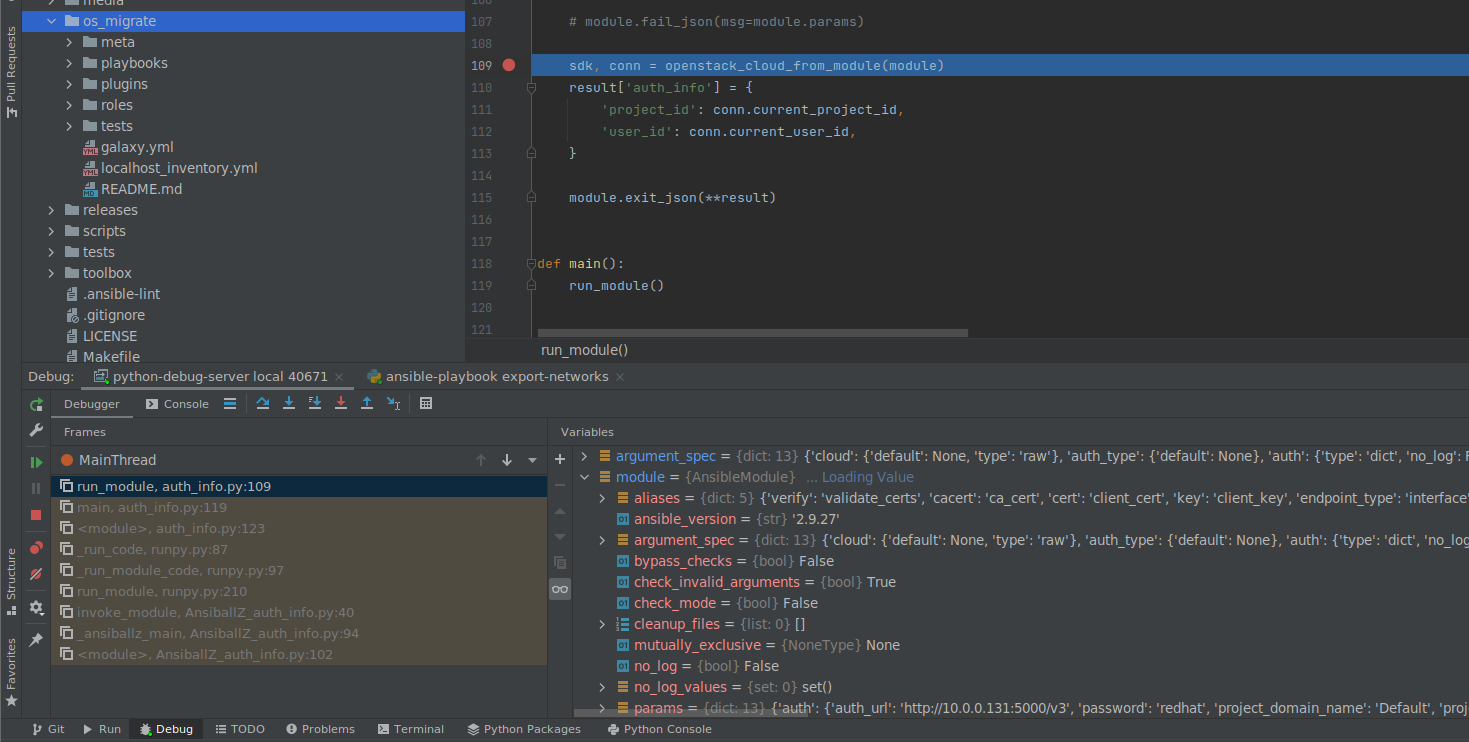
I have found this very helpful in being able to quickly iterate on changes to code in an ansible collection instead of having to wait for each `ansible-playbook` run to complete.